
はじめに
今回はNext.jsプロジェクトでGoogleの生成AIであるGeminiのAPIを使用する方法を解説します。
GeminiはGoogleの生成AIで、chatGPTと比較されることが多いです。
私の体感ですが、chatGPTの方が安定して人間らしい回答をしてくれる印象があります。
ただ、Geminiも常に進化し続けていまして、先日発表された、Gemini pro1.5では1000万トークンの入力が可能になっております。
今後の発展に期待して、今回はGeminiのAPIを使う方法について解説します。
今回は主に公式リファレンスを参考に解説します。
筆者の環境
・OS:Windows11
・CPU:Ryzen9 3900X
・エディタ:VScode
・Next.jsではapp router使ってます



Next.jsでGeminiを使用する
前提条件
- Next.jsプロジェクトが既にセットアップされていること。
- Next.jsのセットアップ方法についてはこちらの記事をご覧ください。
APIキーの取得
こちらのサイトからGeminiのAPIキーを取得します。
「Get API key in Google AI Studio」を選択

「Get API key」を選択
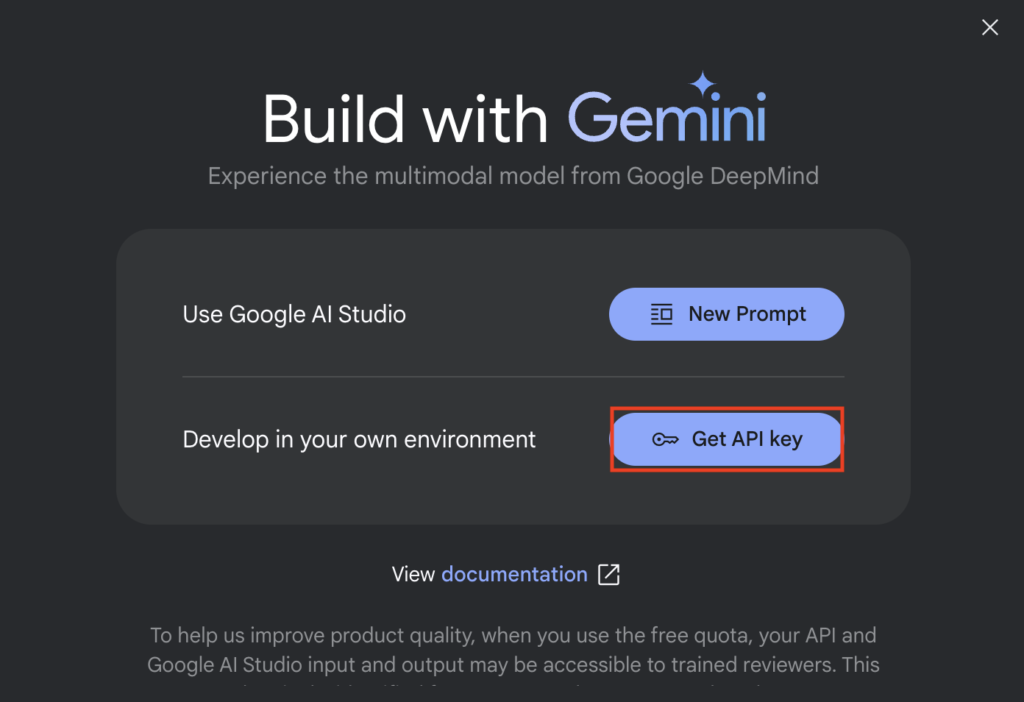
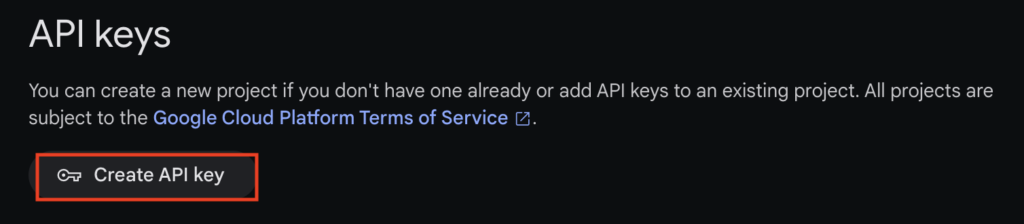
Create API keyでAPI keyの取得が可能。
現在無償期間中なのか、特にクレジットカードの登録などなしに取得できてしまう。
確か60リクエスト/1分まで無料だとかなんだとか・・・
ここで取得したAPIキーはどこかに保存しておきましょう。
環境変数の設定
プロジェクトのルートに.env.localファイルを作成し、以下の環境変数を設定します。
GEMINI_API_KEY=G-XXXXXXXXXXG-XXXXXXXXXXは、取得したAPIキーです。
SDKパッケージをインストール
以下のコマンドでインストール
npm install @google/generative-ai --saveGemini APIを使用する
次にapp/api/gemini-api/route.tsを作成する。
route.tsに以下のプログラムを書きます。
import { GoogleGenerativeAI } from "@google/generative-ai";
import { NextResponse } from "next/server";
export async function POST(req: Request) {
const { prompt_post } = await req.json();
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY || '');
const model = genAI.getGenerativeModel({ model: "gemini-pro"});
const result = await model.generateContentStream(prompt_post);
const response = await result.response
return NextResponse.json({
message: response.text()
})
}Geminiを実際に動かす(文字のみ)
page.tsx(もしくは作成したコンポーネント)に以下を書く。
const [geminiResponse, setGeminiResponse] = useState<string>('');
const prompt = 'こんにちは';
const Gemini = () => {
const postData = async () => {
const response = await fetch('/api/gemini-api', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ prompt_post:prompt }),//promptに入力する文字を入れる
});
const data = await response.json();
setGeminiResponse(data.message);
};
postData();
};
これはGeminiを使用するための関数の定義
promptという変数にGeminiに投げたい文字列を入れてから投げる。
あとは以下のような感じでGemini()を実行してあげれば使用できます。
<button type="button" onClick={() => Gemini()} >
送信
</button>実行結果は以下のようにすれば順番に表示されます。
{geminiResponse}文字と画像を入力する
画像を入力するには先ほど作成したgemini-api/route.tsを以下のように書き換えます。
import { GoogleGenerativeAI } from "@google/generative-ai";
import { NextResponse } from "next/server";
export async function POST(req: Request) {
const { prompt_post,base64Image,mimeType } = await req.json();
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY || '');
const model = genAI.getGenerativeModel({ model: "gemini-pro-vision"});
const base64Data = base64Image.split(',')[1]
const result = await model.generateContentStream(prompt_post,{inlineData:{data:base64Data,mimeType}});
const response = await result.response
return NextResponse.json({
message: response.text()
})
}変更点は以下です。
入力に画像と、画像の型を追加します。
const { prompt_post,base64Image,mimeType } = await req.json();次にbase64に変換した画像のデータ部分の取得
const base64Data = base64Image.split(',')[1]Geminiに入力するデータに画像情報を入れます。
const result = await model.generateContentStream(prompt_post,{inlineData:{data:base64Data,mimeType}});画像をBase64に変換する関数は以下です。
画像を圧縮して、Base64に変換しています。
base64Imageに画像データ、imageTypeに画像の形式が入ります。
const [imageType, setImageType] = useState<string>('');
const [base64Image, setBase64Image] = useState<string>('')
const handleFileChange = (e: React.ChangeEvent<HTMLInputElement>) => {
if (e.target.files) {
const file = e.target.files[0]
setImageType(file.type);
const compressedFilePromise = new Promise<Blob>((resolve, reject) => {
new Compressor(file, {
maxWidth: 512, // 最大幅を512pxに設定
maxHeight: 512, // 最大高さを512pxに設定
quality: 1, // 圧縮品質を設定
success(result) {
console.log(`圧縮された画像のファイルサイズ: ${(result.size / 1024).toFixed(2)} KB`);
resolve(result);
},
error(err) {
reject(err);
},
});
});
// すべてのファイルが圧縮された後、Base64にエンコード
compressedFilePromise.then((compressedFile:Blob) => {
// FileReaderを使用して圧縮された画像をBase64にエンコード
const reader = new FileReader();
reader.readAsDataURL(compressedFile);
reader.onload = () => {
const base64Image = reader.result as string;
setBase64Image(base64Image);
};
});
}
}あとは文字列の送信と同様に以下のように投げます。
const [geminiResponse, setGeminiResponse] = useState<string>('');
const prompt = 'この画像には何が映っている?';
const Gemini = () => {
const postData = async () => {
const response = await fetch('/api/gemini-api', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ prompt_post:prompt ,base64Image:base64Image,mimeType:imageType}),
});
const data = await response.json();
setGeminiResponse(data.message);
};
postData();
};違いはbodyの場所のみです。
文字列のみだけではなく、画像の情報も投げます。
body: JSON.stringify({ prompt_post:prompt ,base64Image:base64Image,mimeType:imageType}),実行や結果の表示は文字列のみと同じです。
さいごに
今回はNext.jsでのGeminiの使い方を解説しました。
私はchatGPTを使用していたら、速度が遅くてGeminiを使ってみようと思いました。
使い方は比較的簡単で、速度も速くていいかなと思いましたが、やはり精度がネックですね。
GPT3.5と似たような立ち位置かなと思います。
といっても、私はGoogle信者ですので、Geminiの進化に期待してしばらく使ってみようかと思います。
パラメータのチューニングなどもできそうなので、後日記事を書こうかと思っています。
では!

コメント